%20(2).png)
.svg)
Introducing RunLLM v2

When we started building the first AI Support Engineer two years ago, we knew that trust was everything. To earn our customers’ trust, we knew that building a simple chatbot that did vector search and piped documents into GPT-4 to generate an answer wouldn’t cut it. And so RunLLM was built to handle different types of data, develop product expertise, respect customers’ preferences, and enforce strict guardrails — all before it even attempted a response.
That early focus on answer quality was justified and helped us earn the trust of companies like Databricks, Sourcegraph, Corelight, and Monte Carlo Data. But as we’ve spent more time with these customers, we realized that answering questions was only the start. A good support engineer does so much more.
Over the past six months, we’ve rebuilt RunLLM from the ground up. Trustworthy answers remain at the core of what we do, but we’ve redesigned the product to better match how our customers work and where we can best help.
From v1 to v2
RunLLM (as with most AI products in 2023) started off as a chat system — we built 100s of data pipelines, fine-tuned custom LLMs, and composed 30+ LLM calls per question, all to generate the highest quality answers possible. On top of that foundation, we built features like instant learning, docs analysis + improvements, and topic modeling to help users better manage their assistants.
But providing answers based off static documents is only part of the problem in enterprise support. A good AI Support Engineer needs to do everything from helping debug to managing your support workflow to enabling other teams in the company.
RunLLM v2 is a platform for building AI Support Engineers that work how you work.
Today, we’re excited to share:
- A brand new UI that enables you to create & manage a suite of agents. With RunLLM’s redesigned UI, you can now create a suite of agents for internal & external use and gain detailed visibility into the reasoning behind each action. You also can customize each agent’s behavior and teach the agent to triage tickets how you do. The new interface is available for everyone to try out today, and we’d love your feedback.
- Custom workflows that match your team’s processes. Our new Python SDK gives every support team control over where RunLLM lives and how it handles different situations — for example, you can build a workflow that triages a new message in Slack, escalates the conversation to Zendesk, and posts a summary to Confluence on resolution. The Python SDK is in private beta with a handful of customers — please reach out if you’re interested!
- Agentic reasoning that can solve your hardest problems. To help resolve more tickets, we can’t stop with what’s written down in your docs. We’ve implemented a new reasoning engine and added support for tool use across log retrieval, telemetry analysis, and custom MCP servers (coming soon). After all, it wouldn’t be a launch in 2025 without agents! Our new reasoning system is in production, and we’re actively rolling out tool use with select customers today.
We’ll share deeper dives into the new UI and SDK over the next couple days. But for today, we wanted to focus on the latest agentic capabilities.
Why Agents?
The first version of RunLLM was the most trusted answer engine in technical support, but answering questions is only one part of the job.
Dating back to last summer, we were building systems that analyzed docs, surfaced inconsistencies, and suggested improvements. This system took actions on your behalf, but we hesitated to use the word "agent." Too much hype, too little substance.
But over the last six months, the agentic feature requests* kept coming: customers wanted help with everything from log analysis to bug detection & escalation. While it was tempting, we realized we couldn’t just bolt this on to the existing product. To do it right, we had to rebuild RunLLM to reason, act, and integrate naturally into a wide variety of existing workflows. A simple hard-coded sequence of LLM calls wouldn’t cut it (sorry RunLLM v1).
Reasoning, Control, and Visibility
The ability to reason about hard problems while enforcing strong guardrails is the foundation of any agentic system. That’s what enables all other actions an agent might take. But the more work an agent does on your behalf, the more you'll want control and visibility over why the system did what it did. That was an area of RunLLM we needed to expand.
RunLLM v1 was built on a static workflow graph of LLM calls — strong guardrails, but limited adaptability, especially when it came to more complex tasks that required multiple search-and-analysis steps. RunLLM v2 introduces an agentic planner that has the flexibility to analyze questions, ask for clarification, search across static & dynamic data sources, refine its search criteria, and a whole lot more.
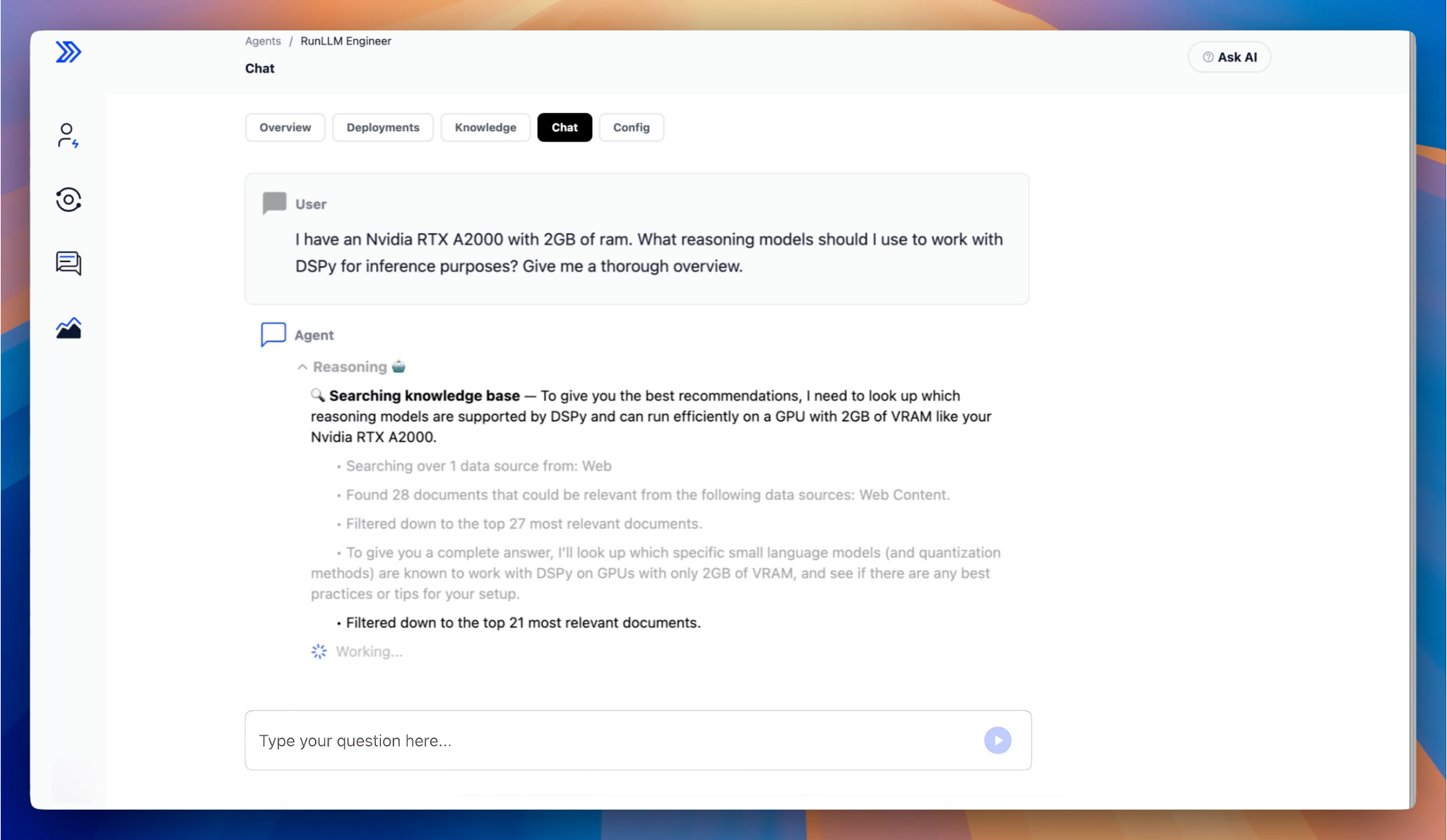
At every step, the system explains itself: how it interpreted the question, what it’s looking for, whether something’s missing, and what led to the final answer. It shows you that reasoning wherever you’re using it. To be transparent (😉), we’ll be adding more on this front — while you can already correct answers and share general guidance, we plan to enable you to give fine-grained feedback to the reasoning process.
Tool Use: Smarter Answers Through Action
Everything until this point sets the stage for one of our most requested features: log and telemetry analysis. Documentation sites, past support tickets, and API specs can help answer some portion of customer requests, but the hardest tasks require digging into system internals. LLMs are great at solving these problems, but they need to be provided the right context at the right time.
Once we felt confident in our planner’s capabilities, integrating into logging & telemetry tools was the natural next step. We’ve already built connectors to Datadog, Splunk, GCP Logging, and Grafana, with more systems coming soon.
You simply need to tell RunLLM what type of data lives in each system. When it receives a relevant question, it decides whether log analysis is helpful, queries the data, filters the noise, and checks if any past issues or documentation match. It will identify what went wrong for you and when possible will suggest a solution immediately.
What’s Next
This is just the beginning.
In the months ahead, we’re adding per-user and per-company memory, deeper integration with custom MCP servers, expanded agent actions, and support for issue reproduction.
We’re deeply grateful to the teams who’ve helped shape this product. RunLLM is already the most productive AI Support Engineer on the market, and we’re just getting started.
Stay tuned for deeper dives into our new UI and workflow customizations.
👉 Try RunLLM v2 now →
🎉 Join our launch today on Product Hunt →
*Requests for agents, not by agents thankfully!
Read the Latest



.webp)


